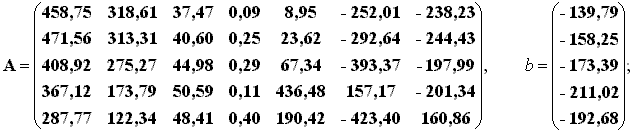
На правах рукописи
МЕТОДЫ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ПОИСКА НАУЧНОЙ ИНФОРМАЦИИ
(НА МАТЕРИАЛЕ INTERNET)
Специальность 05.13.16 - Применение вычислительной техники, математического моделирования и математических методов в научных исследованиях
АВТОРЕФЕРАТ
диссертации на соискание ученой степени
кандидата технических наук
Екатеринбург - 2000
Работа выполнена на кафедре вычислительной техники Уральского государственного технического университета - УПИ
| Научный руководитель: | доктор технических наук, профессор Гольдштейн С.Л. |
| Официальные оппоненты: | доктор технических наук, профессор Чапцов Р.П.
кандидат физико-математических наук, доцент Прохоров В.В. |
| Ведущая организация: | УралВЭС |
Защита диссертации состоится 27 декабря 2000 г. в 13 ч. 00 мин. в ауд. Р-237 на заседании диссертационного совета К 063.14.13 в УГТУ-УПИ.
Отзывы на автореферат в двух экземплярах, заверенные печатью учреждения, просим направлять по адресу: 620002, Екатеринбург, ул. Мира, 19, УГТУ-УПИ, Ученому секретарю.
С диссертацией можно ознакомиться в библиотеке УГТУ-УПИ.
Автореферат разослан 25 ноября 2000 г.
Ученый секретарь диссертационного совета
Морозова В.А.
Актуальность темы. Эффективность научно-исследовательских работ напрямую зависит от качества их информационного обеспечения, а поиск информации является ключевым этапом любого научного исследования. На сегодняшний день глобальная сеть Internet - важнейший источник информации для всех областей знаний, однако поиск специализированной научно-технической информации при помощи Internet зачастую оказывается малоэффективным.
В последние годы мы наблюдаем бурный рост Internet, что ведет к все большему разнообразию информационного наполнения сети. По мере развития Internet обостряется парадокс: вероятность присутствия необходимой информации в глобальном информационном пространстве растет, а вероятность ее нахождения - уменьшается. Это происходит потому, что наполнение сети очень разнородно, громадно по объему, быстро обновляется, плохо поддается структуризации и управлению.
В настоящее время в Internet представлены два основных вида служб поиска информации: тематические каталоги ресурсов и машины поиска (МП) по ключевым словам. Эти универсальные средства обладают целым рядом недостатков с точки зрения поиска научной информации.
Процесс отнесения документа к одному из разделов тематического каталога не поддается полностью автоматизации, поэтому каталоги охва-тывают ограниченное количество ресурсов и "не успевают" за ростом сети.
Машины поиска по ключевым словам охватывают больше ресурсов и чаще обновляются. Однако нередко они оказываются малоэффективными с точки зрения поиска научной информации из-за большого уровня шума (ссылок на нерелевантные документы), ограниченных возможностей языков запросов и формы представления результатов поиска.
Поэтому сегодня особую актуальность приобретают исследования, направленные на повышение эффективности поиска научной информации в Internet. Решение проблемы лежит в области разработки теоретических основ, методов и средств использования слабо структурированных информационных баз в научных исследованиях.
Целью работы является разработка методов повышения эффективности поиска научной информации на материале документов Internet.
Задачи исследования. Для достижения указанных целей в работе поставлены и решены следующие задачи:
Объекты и методы исследования. Объекты исследования - русскоязычные текстовые документы сети Internet, а также механизмы поиска информации в Internet. Для их исследования использовались положе-ния теории информационного поиска, функциональной стилистики, терминоведения, а также методы прикладной статистики и элементы дискретной математики.
Научная новизна работы состоит в следующем:
Практическая ценность. Разработанные методы повышения эффективности поиска научной информации реализованы в виде макетных версий программ стилистического анализа и ассистента формирования запросов на основе тезауруса. В работе предложены эффективные с точки зрения практического использования структурные схемы поиска научной информации с применением разработанных методов.
Реализация результатов. Разработанные программы прошли испытания и внедрены в компании "Конвекс" (Екатеринбург), Свердловской областной универсальной научной библиотеке им. В.Г.Белинского (СОУНБ), НИИ ЦветМет (Екатеринбург). Результаты работы используются в научных исследованиях и учебном процессе на кафедре риторики и стилистики русского языка Уральского государственного университета и на кафедре вычислительной техники Уральского государственного технического университета-УПИ.
На защиту выносятся:
Апробация работы. Основные результаты и положения работы докладывались и обсуждались на XXXV Международной научной студенческой конференции "Студент и научно-технический прогресс" (Новосибирск, 1997), всероссийской конференции "Информационные технологии, системы управления и электроника" (Екатеринбург, 1997), семинаре "Методы прикладной математики и информационные технологии в многодисциплинарных исследованиях и проектах" (Омск, 1998), 30-й региональной молодежной конференции "Проблемы теоретической и прикладной математики" (Екатеринбург, 1999), четвертом и пятом рабочих совещаниях по электронным публикациям EL-PUB-99 и EL-PUB-2000 (Новосибирск, 1999 и 2000), рабочем совещании "Новые Интернет-технологии" (Петрозаводск, 2000).
Публикации. Основное содержание работы опубликовано в 5 печатных и 3 электронных работах.
Структура и объем. Диссертация состоит из введения, четырех глав, заключения, библиографического списка из 83 источников и шести приложений. Общий объем работы - 158 страниц машинописного текста. Работа содержит 59 рисунков и 20 таблиц.
Во введении обоснована актуальность темы, сформулированы цели и задачи работы, кратко изложены результаты работы, их научная новизна и практическая ценность.
Первая глава содержит исторический очерк развития Internet и средств поиска информации, изложение основ построения информационно-поисковых систем (ИПС) Internet; данные об информационном наполнении и аудитории российского сегмента Internet; обзор российских машин поиска и основных направлений совершенствования средств поиска информации в Internet. Кроме того, в первой главе рассматриваются различные подходы к проблеме стилей речи и языка, сделан обзор применения методов прикладной статистики в стилистике и опытов по классификации текстов; дается краткий исторический очерк и обзор применения тезаурусов в информационном поиске.
На протяжении всей краткой, но бурной истории Internet развитие средств поиска шло параллельно с развитием самой сети. Появление "мировой паутины" (WWW) придало этому процессу новую динамику. Современные МП Internet во многом реализуют идеи, которые были сформулированы еще в 70-х гг. для традиционных (локальных) ИПС.
Российский Internet (или Рунет), история которого ведется с конца 80-х - начала 90-х гг., демонстрирует устойчивые темпы роста, повторяя в миниатюре все мировые тенденции. В настоящее время объем российского сегмента Internet оценивается в сотни тысяч серверов и десятки миллионов уникальных страниц.
На сегодняшний день в Рунете действует три "большие" машины поиска: "Апорт", "Рэмблер" и "Яндекс". Они несколько различаются по объемам проиндексированной информации, возможностям языков запросов, методам ранжирования результатов поиска. Наличие нескольких поисковых служб, выполненных на высоком технологическим уровне, является, безусловно, большим достижением российского Internet. Однако все эти МП обладают целым рядом недостатков с точки зрения поиска научной информации.
Вторая глава посвящена разработке процедуры автоматической классификации документов по стилям.
В качестве рабочей была выбрана концепция функциональной стилистики и соответствующая ей система пяти стилей русской речи (разговорный, художественный, публицистический, официально-деловой и научный).
Из прикладного характера поставленной проблемы следует, что метод классификации должен быть достаточно простым в вычислительном плане. Из задачи автоматической классификации текстов по стилям вытекает задача автоматического вычисления параметров текстов. Параметры так же должны быть легко вычислимыми, а их набор - по возможности оптимальным.
Процесс получения набора параметров классификации разбивается на два этапа. На начальном этапе формируется первичный набор параметров "с запасом". Два фактора являются решающими для включения параметра в первичный набор: легкая вычислимость и потенциальная значимость для задач стилистической классификации. Второй этап - оптимизация набора параметров.
Из требования "простоты" вытекает, что параметры берутся в основном с "нижних" уровней языковой системы (графики, лексики, морфологии) и имеют формальный характер. За базовую единицу для вычисления параметров принимается отдельное слово.
Все параметры первичного набора можно разделить на формальные и формально-семантические (табл. 1).
Таблица 1
Первичный набор параметров
Уровень языка
Параметры
формальные формально-семантические
Графика формулы :) - smiles
Cловообразование
--
приставки, характерные для научного стиля
Лексика
средняя длина слова
Морфология
Синтаксис
доля предложений с подчинительными союзами
Параметры первой группы - это либо подсчет определенных знаков (разделителей между словами или предложениями; формул), либо определенных грамматических характеристик слов. Вычисление формально-семантических параметров - это сравнение каждого анализируемого слова с элементами заданных списков (использование "словарей").
В первичном наборе содержится 31 параметр (из них 12 характеризуют распределение слов текста по частям речи). Разработана методика вычисления параметров.
В качестве метода для построения классификации выбран дискриминантный анализ (ДА).
Взятая за основу функционально-стилевая концепция определила подход к формированию опытного массива документов ("обучающей выборки" в терминах ДА).
Официально-деловой стиль представлен в опытном массиве текстами 50 законов Российской федерации. В коллекцию документов научного стиля вошли 54 статьи по физике, математике, химии, биологии и инже-нерным наукам. Публицистический стиль представлен статьями на общественно-политические темы, опубликованными на трех новостных веб-сайтах: Gazeta.ru, Vesti.ru и Polit.ru - всего 61 статья. Образцы художественного стиля - 79 рассказов участников конкурса сетевой литературы "Тенета-98". Тексты разговорного стиля - это 48 фрагментов листингов чатов и 13 диалогов, которые велись с помощью программы ICQ (14 разных участников). Общий объем опытного массива - 305 документов.
После вычисления параметров опытного массива была проведена первичная статистическая обработка результатов. Для каждого параметра вычислены минимальные, максимальные, средние значения и стандарт-ные отклонения по каждому стилю; проведены тесты на нормальность распределения, вычислена выборочная матрица корреляции.
На основании анализа полученных результатов из 31 параметра первичного набора были исключены 10. Основанием для исключения пара-метра из набора были малая вариабельность средних значений по стилям, большая дисперсия, отличие поведения параметров от предполагаемого a priori.
Наличие групп взаимно коррелированных параметров говорит о возможности сокращения набора параметров классификации.
В первом эксперименте по классификации опытного массива мы использовали 14 параметров из 21. Семь параметров не могли быть включены в модель, так как они имеют нулевые дисперсии в одном или нескольких классах (стилях). Полученная дискриминантная функция хо-рошо работает на документах опытного массива: в целом ошибки составляют менее 10%, для документов научного стиля - менее 8%.
С помощью последовательных процедур ДА была получена оптимизированная дискриминантная функция семи параметров в виде
s = Ax+b,
где А - матрица коэффициентов; b - вектор констант:
х - вектор параметров документа (х1 - доля глаголов, х2 - доля наречий, х3 - средняя длина слова, х4 - средняя длина предложения, х5 - доля слов общенаучной лексики, х6 - доля слов с научными корнеаффиксами, х7 - доля слов-названий официальных документов).
Отнесение к одному из пяти стилей происходит из условия макси-мума соответствующей компоненты вектора s (s1 - разговорный, s2 - художественный, s3 - публицистический, s4 - научный, s5 - официально-деловой).
Функция демонстрирует высокое качество классификации документов научного стиля - ошибки составляют менее 8% (табл. 2).
Таблица 2
Классификация опытного массива
Художественный
Стиль Разго-
ворный Художест-
венный Публици-
стический Научный Офици-
ально-
деловой Класси-
фицировано
правильно, %
Разговорный
56 5 0 0 0 91,80
9 61 9 0 0 77,22
Публицистический
0 3 58 0 0 95,08
Научный
0 0 2 50 2 92,59
Официально-
деловой
0 0 1 0 49 98,00
Всего
65 69 70 50 51 89,84
Применение методов канонического дискриминантного анализа позволяет выявить геометрическую структуру классов. Документы научного стиля на диаграмме рассеяния в координатах канонических направлений образуют изолированный кластер (рис. 1).
Первое каноническое направление является линейной комбинацией семи параметров текста (смысл параметров х1, ..., х7 см. выше):
R1 = 18,44·х1 + 22,35·х2 - 1,36·х3 - 0,01·х4 - 37,74·х5 - 15,41·х6 - 31,07·х7 + 5,73
и отражает бoльшую часть стилистического разнообразия документов. Хотя четкие границы между стилями отсутствуют, пучки, соответствую-щие документам публицистического, художественного и разговорного стилей, располагаются последовательно вдоль первого канонического направления. Второе каноническое направление хорошо разделяет документы научного и официально-делового стилей, а вариации документов остальных стилей вдоль этого направления незначительны.
Анализ этих результатов позволяет на основе первого канонического направления ввести показатель стилистической информативности документа и использовать его в процессе информационного поиска.
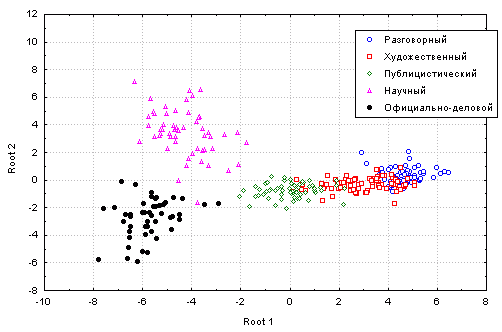
Рис. 1. Диаграмма рассеяния документов опытного массива
(Root 1 - первое каноническое направление,
Root 2 - второе каноническое направление)
С помощью метода главных компонент получены два фактора, которые являются линейными комбинациями 21 параметра первичного набора. Геометрическая структура классов (стилей), которая выявляется на диаграмме рассеяния объектов опытного массива в новых координатах (рис. 2), аналогична полученной при помощи канонического ДА (см. рис. 1). Это еще раз подтверждает, что различия между объектами (документами) обусловлены в основном различиями между классами (стилями). Однако в данном случае кластеры выглядят более плотными. Это достигается за счет использования более полного набора параметров.
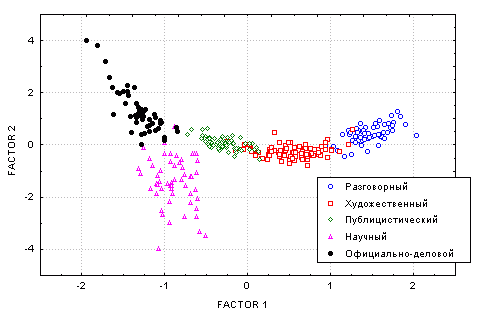
Рис. 2. Диаграмма рассеяния документов опытного массива
(Factor 1 - первый фактор, Factor 2 - второй фактор)
Разработанная программа стилистического анализа состоит из двух блоков - СКАНЕРА и АНАЛИЗАТОРА (рис. 3). СКАНЕР с помощью модуля морфологического анализа (Linguist) и "словарей" вычисляет параметры документа и передает их АНАЛИЗАТОРУ, который вычисляет значения дискриминантной функции и показателя стилистической информативности.
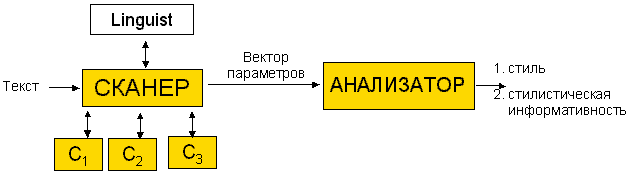
Рис. 3. Структура программы стилистического анализа
Третья глава посвящена методу расширения поискового запроса на основе тезауруса с сильно дифференцированными семантическими отношениями.
В работе делается вывод, что тезаурус может стать эффективным инструментом формирования запросов к универсальным ИПС Internet и существенно повысить эффективность поиска научной информации. Для этого должны выполняться следующие условия:
Свойства терминов ограниченной научной области: системность, устойчивость и регулярность взаимосвязей, отсутствие субъективности и экспрессии - делают возможным описание терминологии с помощью тезаурусов.
Особенно точно описать терминологию можно при помощи тезауруса с набором сильно дифференцированных семантических отношений. Основная идея такого описания - использование не только универсальных отношений (например, "род-вид", "часть-целое" и т.д.), но и отношений, специфических для конкретной научной области. Общее количество типов отношений может достигать нескольких десятков. Таким образом, каждый тип отношения сам по себе несет значительную смысловую нагрузку, определяет различные аспекты семантики термина.
Такая структура тезауруса позволяет ввести понятие стратегии поиска по тезаурусу. Стратегия - это шаблон с указанием связки ("И", "ИЛИ", "НЕ") и веса для каждого типа семантического отношения. Выбрав "опорный" термин и применив к нему стратегию, можно получить запрос, в котором опорный термин объединен со своими "соседями" в соответствии с маской-стратегией. Стратегии могут быть направлены как на повышение точности или полноты поиска, так и на выделение определенных понятийных сфер термина. Стратегии сокращают усилия на формирование запросов, а также служат подсказкой начинающему пользователю.
Разнообразие, специфичность и динамика тематических интересов и информационных запросов пользователей ставит под вопрос эффективность централизованной разработки тезаурусов и расположения их на МП. Тезаурусный ассистент формирования запросов целесообразно разместить в клиентской части, на стороне пользователя.
При разработке модели расширения поискового запроса мы использовали синтаксис языка запросов ИПС "Яндекс".
Модель тезауруса мы определяем как упорядоченную тройку:
T = <A, R, В>,
где A - непустое множество терминов (носитель модели);
R - множество типов (символов) бинарных отношений (сигнатура модели);
В - множество бинарных отношений на множестве A, причем имеется отображение множества R в множество В: rОR Ю r(r)ОВ (интерпретация сигнатуры).
Из семантических ограничений следует, что все отношения В нерефлексивны (термин не связан с самим собой).
Множество типов отношений должно оптимально соответствовать терминосистеме, откуда следует, что термин не может быть связан с другим более чем одним типом отношения:
И (r1 З r2) = Ж.
r1№r2
{r1, r2} ОВ
Стратегию поиска по тезаурусу определим как упорядоченную четверку:
S = <w, Rs, js, fs>,
где wО N - вес опорного термина;
Rs Н R - типы связей, участвующих в стратегии;
js : Rs ® {&, |, ~ } - функция, ставящая в соответствие каждому типу отношения из Rs тип связки;
fs : Rs ® N - функция, ставящая в соответствие каждому типу отношения из Rs вес.
Две стратегии S1 и S2 назовем совместимыми, если они либо не пересекаются по задействованным в них типам связей (RS1 З RS2 = Ж), либо значения функций j S1 , j S2 совпадают на этом пересечении (j S1 (x) =j S2 (x), "x О RS1 З RS2).
Для двух совместимых стратегий S1 и S2 следующим образом можно определить объединение S:
S = S1 Е S2 = <w1+w2, RsИ Rs2, js, fs>,
где функции js и fs определяются следующим образом:
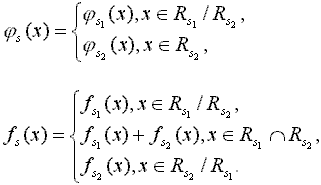
Операция объединения стратегий может быть продуктивна при интеграции нескольких тезаурусов.
Процедура расширения поискового запроса с помощью тезауруса реализована на уровне макета в программе ProThes Q. Структура базы данных, с которой работает программа, представлена на рис. 4.
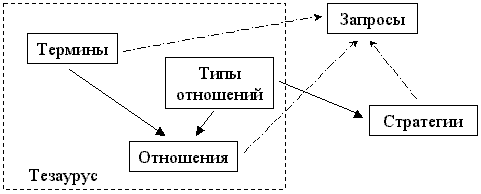
Рис. 4. Структура базы данных программы ProThes Q
Программа содержит три базовых экранных формы: "Термин" (навигация по тезаурусу), "Запрос" (формирование запроса, рис. 5), "Стратегия" (формирование стратегий поиска).
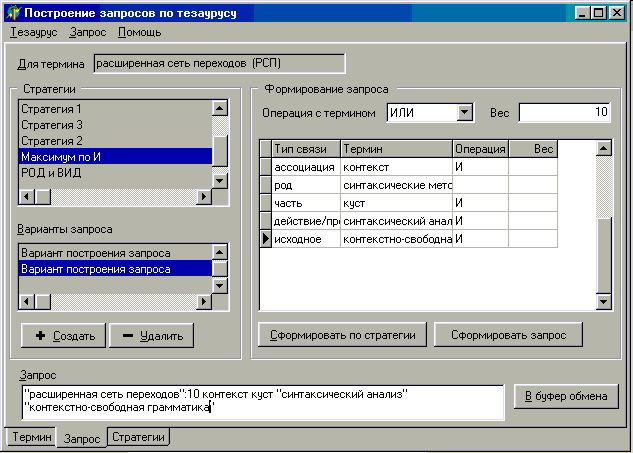
Рис. 5. Форма "Запрос" программы ProThes Q
Четвертая глава посвящена проверке полученных результатов и выработке рекомендаций для их практического применения.
Для проверки метода стилистической классификации был сформирован тестовый массив документов. В массив вошел 71 документ, ссылки на которые выдала поисковая машина "Яндекс" в ответ на запрос "радикал отношение".
Основная часть документов тестового набора принадлежит науч-ному и публицистическому стилям. Можно предположить, что в целом тестовый массив лучше, чем опытный, отражает стилистическую гамму текстов Internet.
Применение полученной дискриминантной функции к документам тестового массива демонстрирует приемлемое качество классификации научных документов - 80% (табл. 3). Причем ошибки классификации научных документов из тестового массива - это отнесение к публицистическому стилю гуманитарных научных статей.
Таблица 3
Классификация тестового массива
Художественный
Стиль Разго-
ворный Художест-
венный Публици-
стический Научный Офици-
ально-
деловой Класси-
фицировано
правильно, %
Разговорный
0 1 0 0 0 0,00
0 1 0 0 0 100,00
Публицистический
0 2 40 0 2 90,91
Научный
0 0 5 20 0 80,00
Всего
0 4 45 20 2 85,92
Заметим, что как при классификации опытного массива, так и при классификации тестового массива к научным не были ошибочно отнесены документы других стилей. Эти результаты подтверждают эффектив-ность метода.
На основании анализа результатов опытов по классификации документов опытного и тестового массивов выработаны рекомендации для применения метода на практике.
Одним из вариантов реализации метода стилистической классификации может быть дополнительный интерфейс к универсальной машине поиска, ориентированный на поиск научных документов. Второй вариант реализации метода состоит в разделении всех найденных документов на "информативные" и "образные".
Кроме того, можно использовать введенный нами показатель стилистической информативности для ранжирования найденных документов. Одновременно пользователь может ограничивать поиск с помощью задания интервала этого показателя.
Для проверки эффективности методики расширения запроса мы использовали тезаурус по компьютерной лингвистике, который содержит примерно 250 терминов и набор из 25 типов семантических отношений.
Отклики ИПС "Яндекс" (табл. 4) позволяют сделать вывод об эффективности предложенного метода расширения запросов.
Таблица 4
Отклики ИПС "Яндекс" на запросы, сформированные при помощи
программы ProThes Q и тезауруса по компьютерной лингвистике
Запрос Количест-
во ссылок
"формальная грамматика" 274
(формальная|контекстно-зависимая|контекстно-свободная| сетевая|трансформационная|зависимостей|"непосредственных составляющих") /1 грамматика 549
"лингвистическая трансляция" 3
"расширенная сеть переходов" 4
слово:10 предложение морфема словосочетание словоформа лексема аффикс 68
фрейм:10 "искусственный интеллект"
15
Во-первых, значительно сокращаются усилия пользователя на формирование запросов. Во-вторых, метод позволяет эффективно управлять полнотой и точностью поиска, а также устранять неоднозначность слов за счет указания семантического окружения.
Однако даже при достаточно специфических запросах, которые формируются из терминов тезауруса, выданные документы могут отличаться по стилю. Это говорит о возможности совместного применения методов, описываемых в работе.
Итоговая структурная схема поиска научной информации представлена на рис. 6.
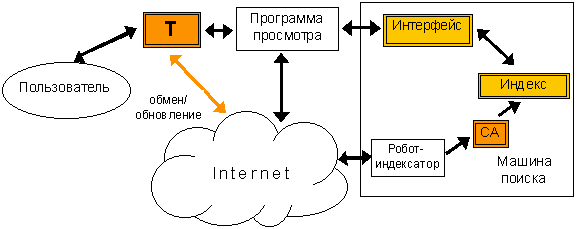
Рис. 6. Итоговая структура поиска научной информации
На этапе индексирования текстовые документы пропускаются через новый блок машины поиска - стилистический анализатор (СА). После этого каждый документ в базе индекса получает дополнительные признаки, связанные с его стилем. Интерфейс предоставляет пользователю новые возможности: ограничение поиска одним стилем или ранжирование выдачи на основе показателя стилистической информативности.
В клиентской части появляется ассистент формирования запросов на основе тезауруса (Т). Заметим, что Internet в этой схеме выступает не только как хранилище информации, но и как среда для коммуникации и объединения усилий разработчиков и пользователей тезаурусов.
Предложенная структура является эффективной с точки зрения развития и совершенствования существующих механизмов поиска.
Предложенные методы позволяют улучшить такие показатели эффективности поиска научной информации, как точность и полнота поиска, усилия пользователя, формат представления результатов.
В результате проведенных исследований предложены методы повышения эффективности поиска научной информации в Internet.
Основные результаты работы заключаются в следующем:
Мы благодарим д-ра филол. наук, профессора Тамару Вячеславовну Матвееву и канд. физ.-мат. наук, доцента Юрия Борисовича Мельникова за участие в обсуждении результатов и содержания работы; компанию "Агама" за предоставленный модуль морфологического анализа; Михаила Щекотилова и Илью Бирюкова - за помощь в создании программ.